


Mogą sięgać nawet 1,6 miliarda dolarów, bo chińska technologia powstała przy użyciu 50 000 procesorów graficznych Nvidia.
Chińska firma DeepSeek wprowadziła niedawno chaos w wielomiliardowym przemyśle AI, wydając model R1, który podobno konkuruje z o1 OpenAI, mimo że został przeszkolony na 2048 Nvidia H800 i kosztował 5,576 miliona dolarów. Jednak nowy raport twierdzi, że rzeczywiste koszty poniesione przez firmę wyniosły 1,6 miliarda dolarów, a DeepSeek ma dostęp do ok. 50 000 procesorów graficznych Hopper.
Twierdzenie, że DeepSeek był w stanie przetrenować R1 przy użyciu ułamka zasobów wymaganych przez duże firmy technologiczne inwestujące w AI, spowodowało spadek ceny akcji Nvidii o rekordowe 600 miliardów dolarów w ciągu jednego dnia. Jeśli chiński startup mógł stworzyć tak potężny model bez wydawania miliardów na najpotężniejsze procesory graficzne AI Team Green, co powstrzymałoby innych przed zrobieniem tego samego?
Ale czy DeepSeek naprawdę stworzył swój model Mixture-of-Experts, który wciąż zajmuje czołowe miejsca w rankingu Apple App Store, przy tak niskich kosztach? SemiAnalysis twierdzi, że nie.
Firma zajmująca się analizą rynku pisze, że DeepSeek ma dostęp do około 50 000 procesorów graficznych Hopper, w tym 10 000 H800 i 10 000 H100. Ma również zamówienia na wiele więcej procesorów H20 specyficznych dla Chin. Procesory graficzne są dzielone między High-Flyer, fundusz hedgingowy za DeepSeek, a startup. Są one rozmieszczone w kilku lokalizacjach geograficznych i wykorzystywane do handlu, wnioskowania, szkolenia i badań.
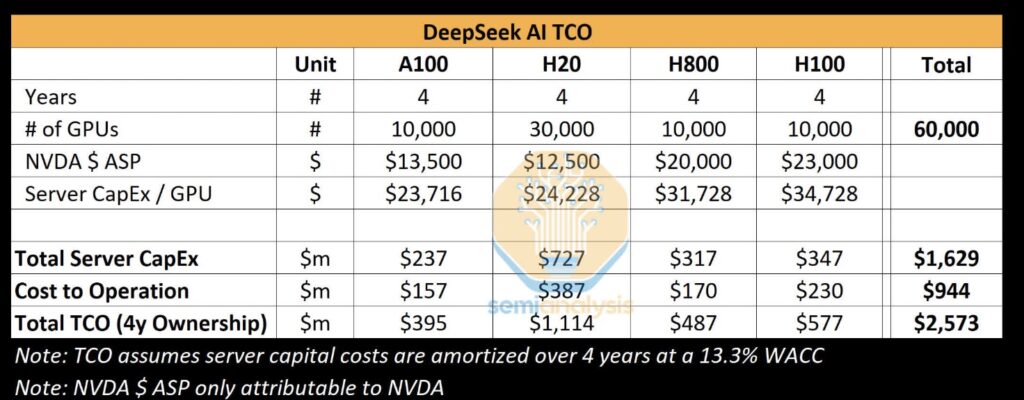
SemiAnalysis pisze, że DeepSeek zainwestował znacznie więcej niż twierdzona kwota 5,5 miliona dolarów, która wywołała zamieszanie na rynku akcji – raport stwierdza, że ten koszt przedtreningowy to bardzo wąska część całości. Całkowita inwestycja firmy w serwery wynosi około 1,6 miliarda dolarów, z około 944 milionami dolarów wydanymi na koszty operacyjne. Inwestycje w procesory graficzne natomiast stanowią ponad 500 milionów dolarów.
Jako przykład referencyjny, Claude 3.5 Sonnet firmy Anthropic kosztował dziesiątki milionów dolarów na szkolenie, ale firma nadal musiała pozyskać miliardy dolarów inwestycji od Google i Amazon.
Zauważono, że DeepSeek pozyskuje cały swój talent wyłącznie z Chin. To kontrastuje z raportami o innych chińskich firmach technologicznych, takich jak Huawei, próbujących pozyskiwać pracowników z zagranicy, przy czym pracownicy tajwańscy z TSMC są bardzo poszukiwanymi celami. DeepSeek rzekomo oferuje wynagrodzenia przekraczające 1,3 miliona dolarów dla obiecujących kandydatów, znacznie więcej niż płacą konkurencyjne chińskie firmy AI.
DeepSeek ma również przewagę, polegającą na tym, że w większości prowadzi własne centra danych, zamiast polegać na zewnętrznych dostawcach chmury. To pozwala na więcej eksperymentów i innowacji w całym stosie produktów AI. SemiAnalysis pisze, że jest to obecnie najlepsze laboratorium “open weights”, przewyższające wysiłki Meta z Llama, Mistral i innych.
Czytaj też: