

Generowanie obrazów przez sztuczną inteligencję to technologia, która w ostatnich latach zyskała znaczną popularność, oferując nowe możliwości w różnych dziedzinach – od sztuki po naukę i biznes. Proces tworzenia obrazów przez AI, choć złożony, jest fascynującym przykładem tego, jak algorytmy mogą naśladować i rozszerzać ludzką kreatywność.
Sztuczna inteligencja: obrazy
Technologia generowania obrazów przez AI, jest rozwijana od kilku dekad, ale zyskała na znaczeniu w ostatnich latach. Wszystko dzięki rozwojowi modeli generatywnych, takich jak Generative Adversarial Networks (GANs, pol. generatywna sieć kontradyktoryjna) i modeli dyfuzji, które umożliwiły tworzenie bardziej złożonych i realistycznych obrazów.
Technologia i modele stojące za generowaniem obrazów przez sztuczną inteligencję
Generowanie obrazów przez sztuczną inteligencję to proces, który w ostatnich latach zyskał na znaczeniu dzięki rozwojowi zaawansowanych modeli generatywnych. Dwie główne technologie stojące za tą zdolnością to Generative Adversarial Networks (GANs) i modele dyfuzji.
Generative Adversarial Networks (GANs)
GANs składają się z dwóch sieci neuronowych, generatora i dyskryminatora, które są trenowane równocześnie w procesie przypominającym grę sumy zerowej. Generator ma za zadanie tworzyć nowe, nierozróżnialne od prawdziwych obrazy, podczas gdy dyskryminator stara się odróżnić obrazy generowane od rzeczywistych. Ten proces współzawodnictwa umożliwia stopniowe doskonalenie obu sieci.
GANs znajdują zastosowanie w tworzeniu realistycznych obrazów, od twarzy ludzkich po scenerie. Są wykorzystywane w grafice komputerowej, w projektowaniu mody, w produkcji filmowej oraz w grach wideo, oferując możliwość generowania wysokiej jakości treści wizualnych.
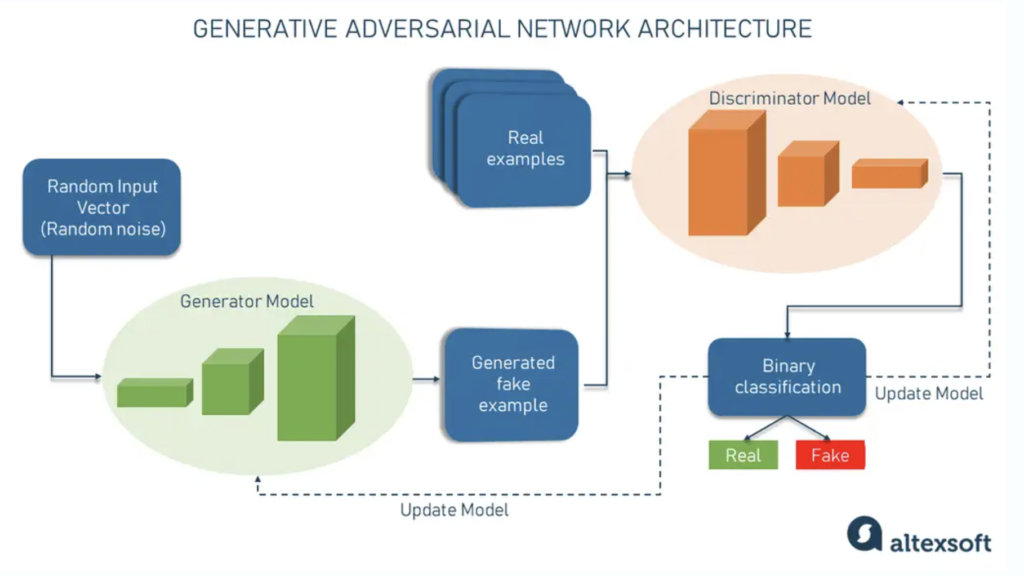
Fot. altexsoft.com
Modele dyfuzji
Modele dyfuzji działają na zasadzie stopniowego dodawania szumu do danych, a następnie uczenia się odwrócenia tego procesu, aby stworzyć nowe, podobne dane. Proces ten rozpoczyna się od danych (np. obrazu), do których dodawany jest szum w serii etapów, tworząc nieczytelne wersje danych, które są stopniowo “oczyszczane” w procesie treningowym, prowadząc do generacji nowych obrazów.
Modele dyfuzji wykazują zdolność do tworzenia wysoce realistycznych i złożonych obrazów. Mogą generować obrazy w różnych stylach, na podstawie tekstowych opisów, co otwiera nowe możliwości w dziedzinach takich jak sztuka cyfrowa, projektowanie produktów czy wizualizacja danych naukowych.
Przykłady zastosowań
- DALL-E. Model generatywny opracowany przez OpenAI, który potrafi tworzyć obrazy na podstawie opisów tekstowych. DALL-E jest zdolny do generowania wyjątkowych wizualizacji, łącząc elementy z różnych kategorii w nowatorski sposób.
- Stable Diffusion. Jest to przykład modelu dyfuzji, który umożliwia tworzenie detalicznych i wizualnie atrakcyjnych obrazów na podstawie opisów tekstowych. Model ten jest szczególnie ceniony za tzw. inpainting (uzupełniania brakujących części obrazu) i outpainting (rozszerzania obrazu).
Pozostała część artykułu pod materiałem wideo:
Jakie trudności ma AI w generowaniu obrazów?
Jednym z głównych wyzwań jest utrzymanie spójności generowanych obrazów, szczególnie gdy chodzi o przedstawianie tych samych postaci w różnych scenariuszach lub z różnych perspektyw. Modele generatywne, takie jak GAN i modele dyfuzji, korzystają z algorytmów, które mogą wprowadzać losowość w generowanych obrazach. Dlatego nawet przy użyciu identycznych wskazówek (promptów), wyniki mogą różnić się od oczekiwanych ze względu na indywidualną interpretację intencji użytkownika przez model.
Inne wyzwania dotyczą technicznych i etycznych aspektów generowania obrazów. AI musi radzić sobie z zapewnieniem spójnego generowania obrazu, kontrolowaniem jakości, pokonywaniem błędów w zbiorach danych, rozwiązywaniem problemów z naruszeniami praw autorskich oraz zarządzaniem wymaganiami obliczeniowymi. Ograniczenia takie jak trudności w generowaniu bardzo szczegółowych obrazów, niespójności wynikające z niewielkich różnic w tekście oraz niemożność proszenia o wyjaśnienia w przypadku niejednoznacznych danych wejściowych stanowią istotne przeszkody.

Wszyscy za jednego według generatora obrazów od OpenAI / Fot. DALLE-3
Nadal istotna jest trudność w generowaniu realistycznych ludzkich twarzy bez defektów. Mimo imponującego postępu, technologie takie jak StyleGAN od NVIDIA, czy systemy DALL-E i Midjourney, nadal borykają się z tworzeniem twarzy i dłoni, które w pełni odzwierciedlałyby rzeczywistą różnorodność ludzką bez drobnych niespójności, takich jak nienaturalne ułożenie zębów czy błędy w przedstawianiu ludzkich palców.
Mimo tych wyzwań, AI oferuje szereg potencjalnych zastosowań, od sztuki i projektowania, przez edukację i marketing, po badania i rozrywkę. Możliwość generowania obrazów obiektów lub scen, które są trudne lub niebezpieczne do sfotografowania w rzeczywistości, otwiera nowe horyzonty dla twórców treści.
Zagrożenia jakie stoją za obrazami AI
Przyszłość generowania obrazów przez AI jest obiecująca, mimo istniejących wyzwań. Dalszy rozwój i udoskonalanie tych technologii niewątpliwie przyniesie nowe możliwości i zastosowania, zmieniając sposób, w jaki tworzymy, uczymy się i bawimy, otwierając przed nami nowe perspektywy kreatywne.
Wśród potencjalnych zagrożeń należy wymienić tworzenie fałszywych obrazów mogących wprowadzać w błąd (deepfakes), naruszenie praw autorskich oraz możliwość wzmocnienia negatywnych stereotypów i uprzedzeń poprzez nieodpowiedzialne użycie technologii.
Czytaj dalej: