


Rozwój modeli językowych, takich jak GPT-4o, wiąże się z ogromnym zapotrzebowaniem na dane tekstowe. Dotychczasowe tempo skalowania sugeruje, że rezerwy treści generowanych przez ludzi mogą wyczerpać się już między 2026 a 2032 rokiem. Problem ten stawia pytania o przyszłość sztucznej inteligencji i jej dalszy rozwój w obliczu ograniczeń zasobów danych. Przyglądamy się wnioskom badaczy z instytutu Epoch AI.
Skalowanie modeli a wyzwania danych
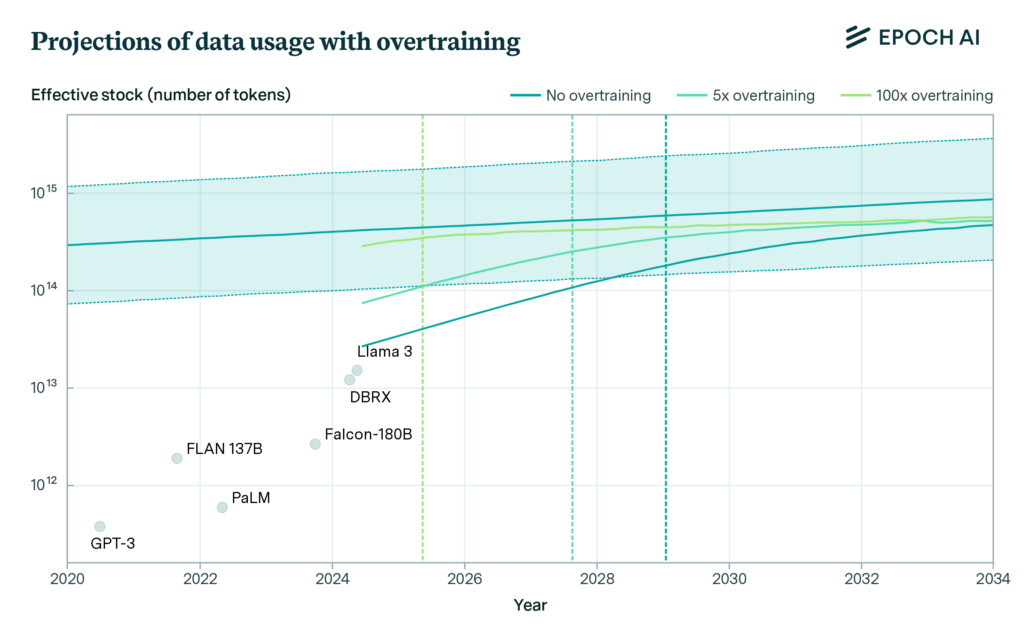
Współczesne modele językowe bazują na miliardach parametrów i bilionach tokenów – jednostek tekstowych odpowiadających fragmentom słów lub całym wyrazom. Szacuje się, że całkowity zasób ludzkiej treści dostępnej publicznie wynosi około 300 bilionów tokenów, z czego jedynie część spełnia standardy jakościowe niezbędne do efektywnego treningu. Przy obecnym tempie rozwoju, modele takie jak Llama 3, które wykorzystują nawet 10-krotnie większe zasoby danych, niż jest to optymalne, mogą wyczerpać te zasoby już do 2025 roku.
Ustalony przedział ufności (80%), zakłada, że zasób danych zostanie w pełni wykorzystany w pewnym momencie między 2026 a 2032 rokiem. Jednak dokładny moment, w którym te dane zostaną w pełni wykorzystane, zależy od tego, jak skalowane są modele. Będą potrzebne kolejne innowacje w obszarze LLM, aby utrzymać postęp po 2030 r.
Wynika z opracowania Epoch AI
Obecnie największe modele są trenowane na zbiorach danych obejmujących teksty z Common Crawl, publikacje naukowe, książki oraz posty w mediach społecznościowych. Jednakże intensywna eksploatacja tych źródeł sprawia, że już teraz dochodzi do wielokrotnego wykorzystywania tych samych zbiorów. Modele są więc “przetrenowywane”, co przyspiesza tempo zużycia dostępnych zasobów.
Dane syntetyczne i inne źródła
Alternatywą dla danych generowanych przez ludzi są dane syntetyczne – treści tworzone przez same modele językowe. Według badań takie podejście pozwala na częściowe uzupełnienie braków, jednak niesie ryzyko obniżenia jakości wyników. Modele mogą zacząć „uczyć się od siebie”, co prowadzi do spadku różnorodności i wartości informacyjnej generowanych odpowiedzi.
Kolejnym kierunkiem jest integracja danych z innych modalności, takich jak obrazy, dźwięki czy wideo. Na przykład, jedna sekunda wideo może być przeliczona na około 30 tokenów tekstowych, co otwiera nowe możliwości, ale nie zastępuje w pełni potrzeby korzystania z tekstu. Nadal to właśnie tekst jest kluczowym zasobem determinującym zdolności modeli językowych.
Czy grozi nam stagnacja w rozwoju modeli?
Choć wizja wyczerpania danych generowanych przez ludzi wydaje się alarmująca, istnieją techniki pozwalające na częściowe złagodzenie tego problemu. Jedną z nich jest „niedotrenowanie” modeli, czyli wykorzystanie mniejszych zbiorów danych, co pozwala na zwiększenie efektywności ich użycia. Tego typu strategie mogą wydłużyć czas dostępności danych o kilka lat, ale ostatecznie nie rozwiążą problemu.
Według szacunków, przy obecnym tempie rozwoju technologii, modele osiągną granice skalowania do 2030 roku, jeśli nie zostaną opracowane nowe metody pozyskiwania danych lub uczenia maszynowego. Innowacje w zakresie efektywności danych, takie jak lepsze filtrowanie i wykorzystanie danych niskiej jakości, mogą odegrać kluczową rolę w dalszym rozwoju.
Przyszłość modeli językowych
Potencjalne wyczerpanie zasobów danych tekstowych generowanych przez ludzi to sygnał ostrzegawczy dla branży AI. Przyszłość może leżeć w bardziej zrównoważonym podejściu do wykorzystania danych oraz w rozwoju technologii, które pozwolą na skuteczne wykorzystanie mniej oczywistych źródeł informacji. Kluczowe znaczenie będzie miało także wsparcie ludzi w procesie tworzenia treści – zarówno tych przeznaczonych do treningu modeli, jak i nowych form danych.
Modele językowe już teraz zmieniają świat – od edukacji po biznes – ale ich przyszłość zależy od tego, czy naukowcy i inżynierowie znajdą sposób na pokonanie ograniczeń wynikających z dostępności danych. W przeciwnym razie grozi nam spowolnienie lub nawet zatrzymanie rozwoju tej przełomowej technologii.
Zobacz również: